[REGRESAR]
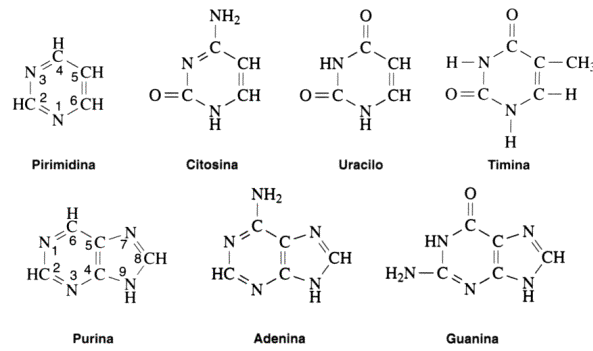
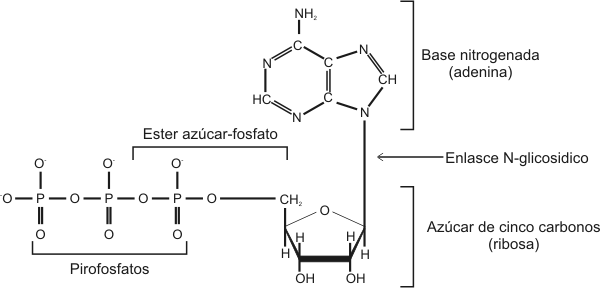
| ÁCIDOS NUCLEICOS Introducción Todas las células contienen la información necesaria para realizar distintas reacciones químicas mediante las cuales las células crecen, obtienen energía y sintetizan sus componentes. Está información está almacenada en el material genético, el cual puede copiarse con exactitud para transmitir dicha información a las células hijas. Sin embargo estas instrucciones pueden ser modificadas levemente, es por eso que hay variaciones individuales y un individuo no es exactamente igual a otro de su misma especie (distinto color de ojos, piel, etc.). De este modo, podemos decir que el material genético es lo suficientemente maleable como para hacer posible la evolución. La información genética o genoma, está contenida en unas moléculas llamadas ácidos nucleicos. Existen dos tipos de ácidos nucleicos: ADN y ARN. El ADN guarda la información genética en todos los organismos celulares, el ARN es necesario para que se exprese la información contenida en el ADN; en los virus podemos encontrar tanto ADN como ARN conteniendo la información (uno u otro nunca ambos). Composición química y estructura de los ácidos nucleicos Los ácidos nucleicos resultan de la polimerización de monómeros complejos denominados nucleótidos. Un nucleótido está formado por la unión de un grupo fosfato al carbono 5’ de una pentosa. A su vez la pentosa lleva unida al carbono 1’ una base nitrogenada. 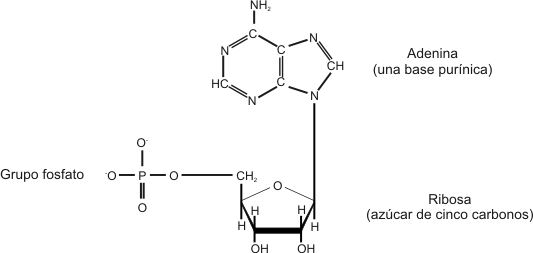 Fig. 2.36 - Estructura del nucleotido monofosfato de adenosina (AMP) Las bases nitrogenadas son moléculas cíclicas y en la composición de dichos anillos participa, además del carbono, el nitrógeno. Estos compuestos pueden estar formados por uno o dos anillos. Aquellas bases formadas por dos anillos se denominan bases púricas (derivadas de la purina). Dentro de este grupo encontramos: Adenina (A), y Guanina (G). Si poseen un solo ciclo, se denominan bases pirimidínicas (derivadas de la pirimidina), como por ejemplo la Timina (T), Citosina (C), Uracilo (U). Estos derivados de la purina y la pirimidina son las bases que se encuentran con mayor frecuencia en los ácidos nucleicos. Fig. 2.37- Bases púricas y pirimídicas
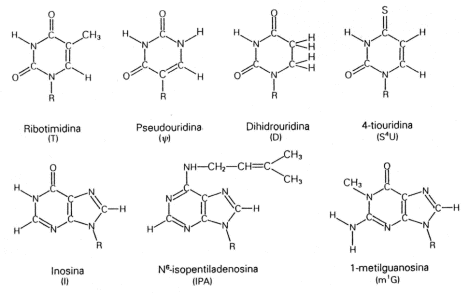
Fig. 2.38 - Bases menos frecuentes Existen otras bases nitrogenadas que son menos frecuentes, algunas de ellas están metiladas. En eucariontes estas bases metiladas participan del control de la expresión genética. Nucleótidos de importancia biológica ATP (adenosin trifosfato): Es el portador primario de energía de la célula. Esta molécula tiene un papel clave para el metabolismo de la energía. La mayoría de las reacciones metabólicas que requieren energía están acopladas a la hidrólisis de ATP.
Fig. 2.39 - ATP (Adenosin trifosfato)
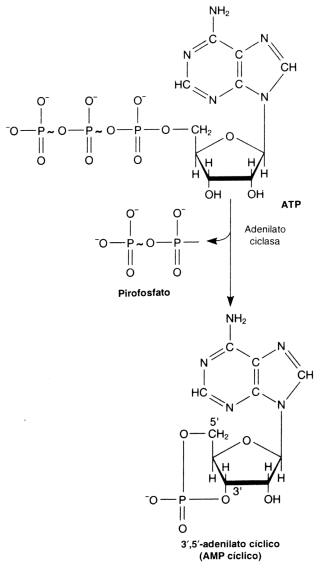
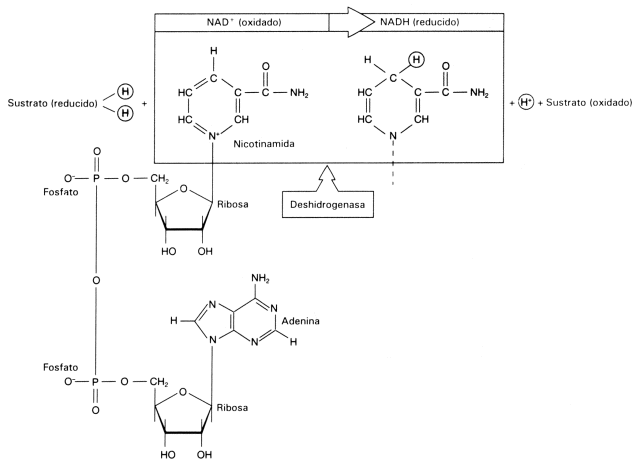
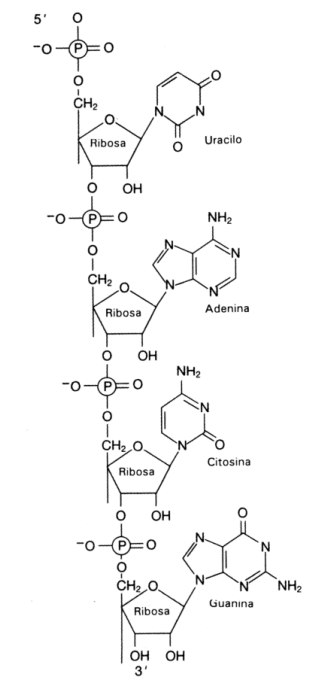
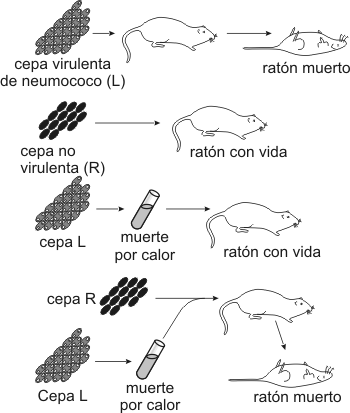
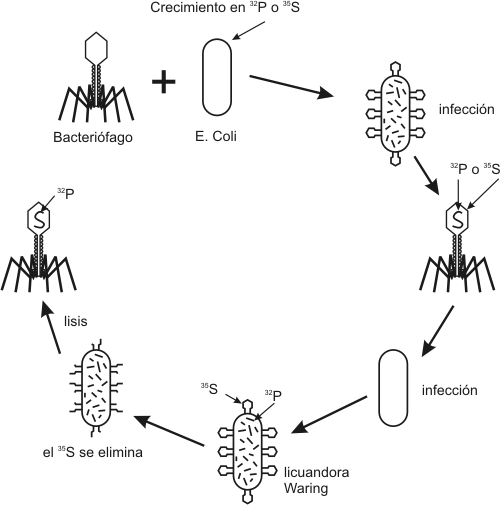
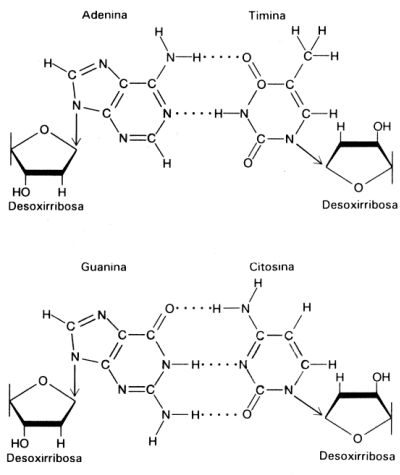
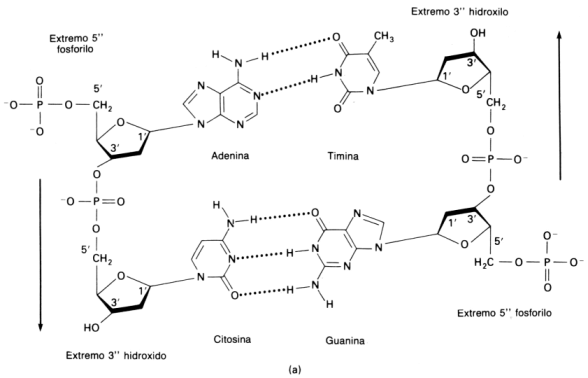
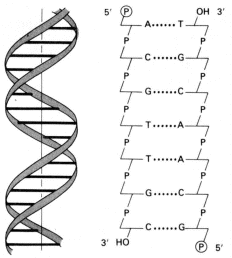
Fig. 2.40 - Estructura del AMPC Este nucleótido posee tres grupos fosfatos unidos entre sí. Estos grupos fosfatos dado el pH celular se encuentran desprotonados, de manera que poseen cargas negativas. Como estas cargas están muy cerca se repelen fuertemente. Para mantenerlos juntos, se establecen uniones de alta energía entre los fosfatos, por lo tanto, cuando la molécula se hidroliza la energía se libera. Del mismo modo para sintetizar una molécula de ATP se requiere energía. AMP cíclico: Es una de las moléculas encargadas de transmitir una señal química que llega a la superficie celular al interior de la célula. segundo mensajero) NAD+ y NADP+: (nicotinamida adenina dinucleótido y nicotinamida adenina dinucleótido fosfato). Son coenzimas que intervienen en las reacciones de oxido-reducción, son moléculas que transportan electrones y protones. Intervienen en procesos como la respiración y la fotosíntesis. Fig. 2.41 - Estructura del NAD+, La nicotinamida acepta hidrogeniones, proceso denominado reducción FAD+: También es un transportador de electrones y protones. Interviene en la respiración celular. Coenzima A: Es una molécula que transporta grupos acetilos, interviene en la respiración celular, en la síntesis de ácidos grasos y otros procesos metabólicos. Polinucleótidos Existen dos clases de nucleótidos, los ribonucleótidos en cuya composición encontramos la pentosa ribosa y los desoxirribonucleótidos, en donde participa la desoxirribosa. Los nucleótidos pueden unirse entre sí, mediante enlaces covalentes, para formar polímeros, es decir los ácidos nucleicos, el ADN y el ARN. Dichas uniones covalentes se denominan uniones fosfodiéster. El grupo fosfato de un nucleótido se une con el hidroxilo del carbono 5’ de otro nucleótido, de este modo en la cadena quedan dos extremos libres, de un lado el carbono 5’ de la pentosa unido al fosfato y del otro el carbono 3’ de la pentosa. Fig. 2.42 - Estructura de un polirribonucleótido ADN – Ácido desoxirribonucleico Los ácidos nucleicos fueron aislados por primera vez en 1869, sin embargo no fue hasta mucho después que se conoció su función. A principio de siglo los científicos que querían explicar como se transmitía y se almacenaba la información genética se enfrentaron a un problema, era el ADN o las proteínas de los cromosomas los que portaban la información genética. Se sabía que el ADN constaba de solo cuatro tipo de monómeros, frente a los 20 aminoácidos que se encuentran formando parte de las proteínas, de manera que se pensaba que era demasiado sencillo como para guardar la información, por lo cual se le asignaba una función estructural. La evidencia que ha servido para esclarecer la función del ADN, ha procedido, por un lado, del hecho que la cantidad de ADN de una especie es constante, sin importar la edad, sexo, factores nutricionales o ambientales. Por otra parte, la cantidad de ADN tiene mayoritariamente una relación directa con la complejidad del organismo, así como también se observa que las gametas de los individuos con reproducción sexual poseen solo la mitad del ADN que posee cualquier de sus células somáticas. Sin embargo esto por si solo no confirmó la función del ADN. Por ello se llevaron a cabo una serie de experimentos que lo demostraron en forma concluyente. En 1928, Griffith experimentó con distintas cepas de bacterias, una de ellas era la forma llamada lisa (L), rodeada de una cápsula de polisacáridos y causante de neumonía en los ratones. En contraste las cepas rugosas, no contenía el polisacárido y no era virulenta. Griffith experimentó con ratones. A unos inyectándoles cepas lisas muertas por calor, a otras cepas rugosas vivas y a otros una mezcla de cepa R viva con cepa L muertas por calor, en este último caso los ratones morían de neumonía, es decir que las células rugosas se habían transformado en cepas virulentas. En 1944 se demostró que ese principio transformador era el ADN y no las proteínas. Fig. 2.43 - Experimento de Griffith Otra serie de experimentos realizados en 1952 por Hershey y Chase, demostraron en forma indiscutible que el ADN es el material genético. Trabajaron con virus llamados bacteriofagos; los bacteriofagos, están formados por ADN y proteínas, las proteínas forman una cubierta y en su interior se aloja el ADN. Se cultivaron virus en un medio que contenía fósforo radiactivo, de manera que al sintetizar su ADN, la molécula quedaba marcada radiactivamente. Otros virus se hicieron crecer en medio con azufre radiactivo, quedando marcadas radiactivamente las proteínas. Los virus tienen un mecanismo de acción muy particular, ya que no ingresan a la célula que infectan sino que solo inyectan su material genético. Luego se pusieron en contacto los virus que poseían las proteínas radiactivas con un cultivo de bacterias y lo mismo se hizo con los virus que tenían el ADN marcado. Fig. 2.44 - Experimento de Hershey y Chase Si la información genética estaba contenida en el ADN la marca radiactiva debía estar en el interior de las bacterias de este último grupo, por el contrario si eran las proteínas las que cumplían dicha función la marca radiactiva estaría adentro de las bacterias del primer grupo. El resultado del experimento confirmó que el ADN era la molécula que buscaban, ya que se encontraba la marca radioactiva en el interior de las bacterias que se pusieron en contacto con ADN marcado. Una vez establecida su función faltaba determinar su estructura, como era posible que esa estructura repetitiva almacenara las distintas instrucciones. En 1953 Watson y Crick propusieron el modelo de doble hélice, para esto se valieron de los patrones obtenidos por difracción de rayos X de fibras de ADN, y de los postulados enunciados por Chargaff que estableció que la cantidad de adenina de una molécula de ADN era igual a la cantidad de timina de la misma molécula y que la cantidad de guanina era igual a la cantidad de citosina, es decir que el contenido de purinas era igual al de pirimidinas. Fig. 2.45 - Pares de bases del ADN: La formación específica de enlaces de hidrógeno entre G y C y entre A y T genera los pares de bases complementarias El modelo de la doble hélice establece que las bases nitrogenadas de las cadenas se enfrentan y establecen entre ellas uniones del tipo puente de hidrógeno. Este enfrentamiento se realiza siempre entre una base púrica con una pirimídica, lo que permite el mantenimiento de la distancia entre las dos hebras. La Adenina se une con la timina formando dos puentes de hidrógeno y la citosina con la guanina a través de tres puentes de hidrógeno. Las hebras son antiparalelas, pues una de ellas tiene sentido 5’ ® 3’, y la otra sentido 3’ ® 5’. El modelo de Watson y Crick, describe a la molécula del ADN como una doble hélice, enrollada sobre un eje, como si fuera una escalera de caracol y cada diez pares de nucleótidos alcanza para dar un giro completo. Excepto en algunos virus, el ADN siempre forma una cadena doble. Factores que estabilizan la doble hélice Los puentes de hidrógeno entre las bases tienen un papel muy importante para estabilizar la doble hélice, si bien individualmente son débiles hay un número extremadamente grande a lo largo de la cadena. Las interacciones hidrofóbicas entre las bases también contribuyen con la estructura. Los grupos fosfatos que se encuentran en el exterior de la doble hélice pueden reaccionar con el agua aportando mayor estabilidad.
Fig.
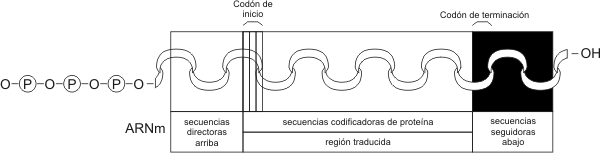
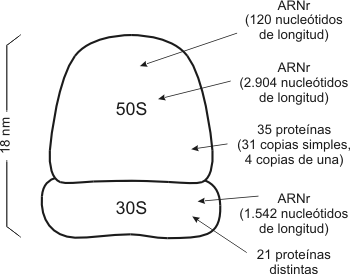
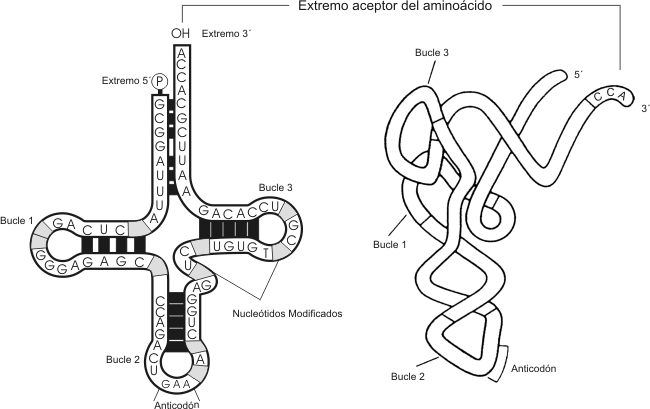
2.46 - Una corta sección de la doble hélice de ADN Fig. 2.47 - (a) Modelo de la doble hélice de ADN, (b) Representación abreviada de un segmento de ADN Funciones biológicas El ADN es el portador de la información genética y a través de ella puede controlar, en forma indirecta, todas las funciones celulares. Debemos recordar aquí que las enzimas son proteínas que catalizan todas las funciones biológicas y se sintetizan en las células de acuerdo a la información genética. Vale decir que a la información genética la podemos comparar con un recetario, donde están las recetas de todas las proteínas del organismo. Encontramos ADN en el núcleo de las células animales y vegetales, en los organismos procariontes, en organoides como los cloropastos y mitocondrias, como así también en algunos virus, a los que llamamos ADN - virus. ARN – Ácido ribonucleíco El ácido ribonucleíco se forma por la polimerización de ribonucleótidos. Estos a su vez se forman por la unión de: a) un grupo fosfato. b) ribosa, una aldopentosa cíclica y c) una base nitogenáda unida al carbono 1’ de la ribosa, que puede ser citocina, guanina, adenina y uracilo. Esta última es una base similar a la timina. En general los ribonucleótidos se unen entre sí, formando una cadena simple, excepto en algunos virus, donde se encuentran formando cadenas dobles. La cadena simple de ARN puede plegarse y presentar regiones con bases apareadas, de este modo se forman estructuras secundarias del ARN, que tienen muchas veces importancia funcional, como por ejemplo en los ARNt (ARN de transferencia). Se conocen tres tipos principales de ARN y todos ellos participan de una u otra manera en la síntesis de las proteínas. Ellos son: El ARN mensajero (ARNm), el ARN ribosomal (ARNr) y el ARN de transferencia (ARNt). ARN mensajero (ARNm) Fig. 2.48 - Esquema de una ARNm bacteriano Consiste en una molécula lineal de nucleótidos (monocatenaria), cuya secuencia de bases es complementaria a una porción de la secuencia de bases del ADN. El ARNm dicta con exactitud la secuencia de aminoácidos en una cadena polipeptídica en particular. Las instrucciones residen en tripletes de bases a las que llamamos codones. Son los ARN más largos y pueden tener entre 1000 y 10000 nucleótidos En los eucariontes los ARNm derivan de moléculas precursoras de mayor tamaño que se conocen en conjunto como ARN heterogéneo nuclear (hnARN), el cual presenta secuencias internas no presentes en ARN citoplasmáticos. ARN ribosomal (ARNr) Este tipo de ARN una vez transcripto, pasa al nucleolo donde se une a proteínas. De esta manera se forman las subunidades de los ribosomas. Aproximadamente dos terceras partes de los ribosomas corresponde a sus ARNr. Fig. 2.49 - Diagrama de un ribosoma procarionte ARN de transferencia (ARNt) Este es el más pequeño de todos, tiene aproximadamente 75 nucleótidos en su cadena, además se pliega adquiriendo lo que se conoce con forma de hoja de trébol plegada. El ARNt se encarga de transportar los aminoácidos libres del citoplasma al lugar de síntesis proteica. En su estructura presenta un triplete de bases complementario de un codón determinado, lo que permitirá al ARNt reconocerlo con exactitud y dejar el aminoácido en el sitio correcto. A este triplete lo llamamos anticodón.
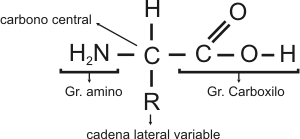
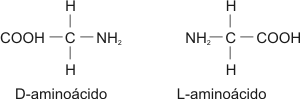
Fig. 2.50- Molécula de ARNt ARN pequeño nuclear (ARNpn o snRNA) En eucariontes encontramos un grupo de seis ARN que están en el núcleo, el ARN pequeño nuclear, estos desempeñan cierto papel en la maduración del ARNm. Ribozimas Son ARN que tienen función catalítica, participan activamente en la maduración de los ARNm. Función de los ARN Un gen está compuesto, como hemos visto, por una secuencia lineal de nucleótidos en el ADN, dicha secuencia determina el orden de los aminoácido en las proteínas. Sin embargo el ADN no proporciona directamente de inmediato la información para el ordenamiento de los aminoácidos y su polimerización, sino que lo hace a través de otras moléculas, los ARN. Todo el proceso que se lleva a cabo para la síntesis de proteínas se verá detalladamente en otro capítulo. Proteínas Las proteínas son las macromoléculas más abundantes en las células animales y constituyen alrededor del 50% de su peso seco. Dentro de las células se las encuentra en formas muy variadas: como constituyente de las membranas biológicas, como catalizadores de reacciones metabólicas (enzimas), interactuando con los ácidos nucleicos (histonas) o con neurotransmisores y hormonas (receptores), etc. Prácticamente, no existe proceso biológico en el que no participe por lo menos una proteína. Se las considera como el grupo de compuestos que mayor cantidad de funciones desempeñan en los seres vivos. Estas moléculas son polímeros de aminoácidos unidos por enlaces peptídicos. Las proteínas pueden ser simples o conjugadas. Las simples sólo están formadas por aminoácidos. Las conjugadas contienen además de la o las cadenas polipéptidicas, grupos no proteicos, denominados grupos prosteicos, por ejemplo la hemoglogina o las lipoproteínas. Para entender los aspectos estructurales y las características químicas de las proteínas, es fundamental analizar primero la de sus monómeros. Aminoácidos Como su nombre lo indica, cada aminoácido está formado por un grupo amino y un grupo ácido carboxílico , unidos a un átomo de carbono central o carbono a, el que además tiene unido siempre un átomo de hidrógeno y una cadena lateral de características variables. Por poseer un grupo amino y un grupo carboxilo, los aminoácidos son anfolítos, dependiendo del pH del medio su comportamiento como ácidos o bases. Fig. 2.51 - Fórmula general de un aminoácido El carbono central es asimétrico ya que está compartiendo electrones con cuatro grupos diferentes, por eso los aminoácidos, con excepción de la glicina, presentan actividad óptica, es decir, tienen isómeros D y L. Solamente las formas L forman parte de las proteínas.
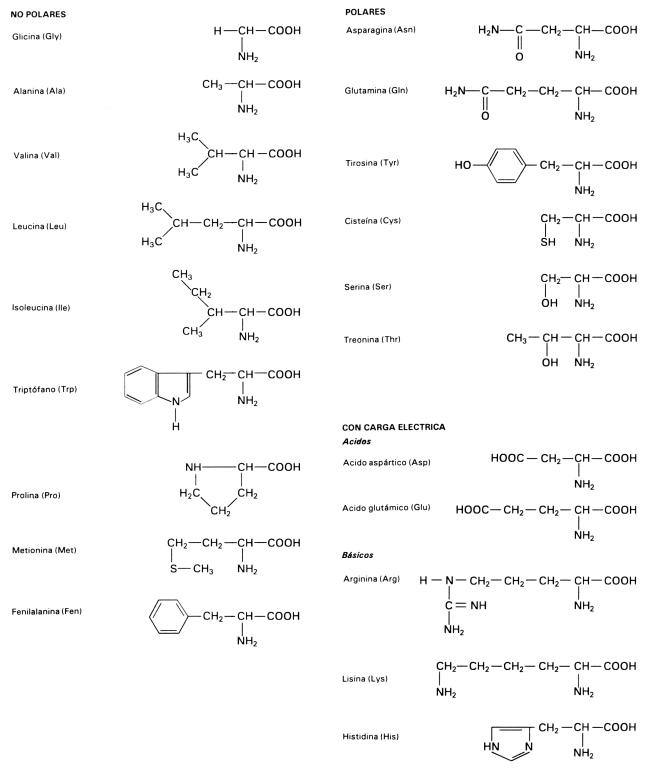
Fig. 2.52 - Fórmula general de los D y L-aminoácidos Como muestra la fórmula, el carbono central se encuentra unido a un grupo variable o resto (R). Es en dichos grupos R, donde las moléculas de los veinte aminoácidos [1] que forman parte de las proteínas se diferencian unas de otras. En la glicina, el más simple de los ácidos, el grupo R se compone de un único átomo de hidrógeno. En otros aminoácidos el grupo R es más complejo, conteniendo carbono e hidrógeno, así como oxígeno, nitrógeno y azufre. De acuerdo con la naturaleza del ”R” podemos clasificar a los aminoácidos en polares (con y sin carga) y aminoácidos no polares. Fig.
2.53 - Estructura química de los veinte aminoácidos clasificados en ácidos,
básicos, neutros polares y neutros no polares. Las estructuras que se
encuentran debajo de los grupos amino y carboxilo son las cadenas laterales
R Aminoácidos esenciales La síntesis proteica requiere de un constante aporte de aminoácidos. Los organismos heterótrofos sintetizan gran parte de estos aminoácidos a partir de esqueletos carbonados. Los que requieren ser incorporados por la ingesta, no pudiendo ser sintetizados, se denominan aminoácidos esenciales, y son producidos por plantas y bacterias (Tabla 2.4).
Aminoácidos y neurotransmisores El impulso nervioso pasa de una célula a otra en el proceso conocido como transmisión sináptica. La transmisión sináptica esta mediada químicamente por moléculas pequeñas llamadas neurotransmisores Se conocen muchos neurotransmisores distintos. Diferentes tipos de neuronas sintetizan distintos neurotransmisores. Por ejemplo el sistema nervioso simpático utiliza la adrenalina y la noradrenalina (catecolaminas), el sistema nervioso parasimpático utiliza acetilcolina. Algunos neurotransmisores derivan químicamente de los aminoácidos. La adrenalina y noradrenalina se sintetizan a partir de la tirosina, este paso ocurre en el citosol de las neuronas adrenérgicas y células adrenales y los neurotransmisores se almacenan en vesículas. El GABA otro neurotransmisor, se sintetiza a partir del ácido glutámico, la histamina a partir de la histidina, la serotonina a partir del triptófano. Cada uno de estos neurotransmisores es sintetizado por neuronas especificas. Fig. 2.54 - Formación de un enlace peptídico Enlaces peptídicos, oligopeptidos y polipeptidos Cuando una célula viva sintetiza proteínas, el grupo carboxilo de un aminoácido reacciona con el grupo amino de otro, formando un enlace peptídico, el producto de esta unión es un dipéptido. El grupo carboxilo libre del dipéptido reacciona de modo similar con el grupo amino de un tercer aminoácido, y así sucesivamente hasta formar una larga cadena. Los oligopéptidos contienen un número indefinido pero pequeño de aminoácidos, mientras que los péptidos y polipéptidos constan de un número mayor. Se consideran polipéptidos a los polímeros de aminoácidos de un peso superior a 6000 Daltons. Muchas moléculas de importancia biológica con acción hormonal e incluso gran parte de los neurotransmisores son oligopéptidos y péptidos, como se observa en los ejemplos citados en las tablas 2.5. y 2.6. Los polipéptidos naturales de 50 o más residuos son considerados proteínas. Una proteína puede estar formada por una sola cadena o por varias de ellas unidas por enlaces moleculares débiles. Cada proteína se forma siguiendo las instrucciones contenidas en el ADN, el material genético de la célula. Estas instrucciones son las que determinan cuáles de los veinte aminoácidos se incorporan a la proteína, y en que orden relativo o secuencia lo hacen. Los grupos R de los diferentes aminoácidos establecen la forma final de la proteína y sus propiedades químicas. A partir de las veinte subunidades pueden formarse una gran variedad de proteínas.
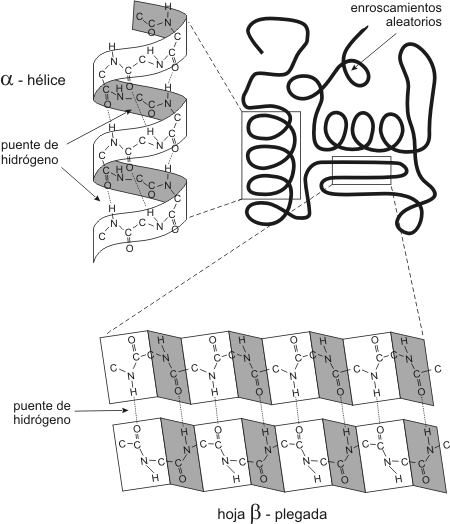
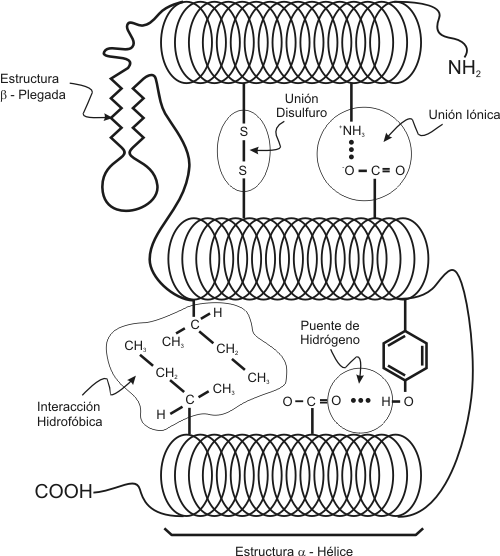
Estructura proteica Estructura primaria Es la secuencia ordenada y única de los aminoácidos en la cadena polipeptídica, la cual está determinada genéticamente. La estructura primaria es fundamental para la forma tridimensional que tendrá la proteína. Cualquier modificación en la secuencia de aminoácidos podría ocasionar un cambio en la estructura tridimensional y afectará la función biológica de la proteína. Fig. 2.55 - Estructura primaria de las dos cadenas polipeptídicas que componen la insulina. La estructura primaria es la secuencia lineal de aminoácidos, cada uno de los cuales está representado en el diagrama por un óvalo. La letra en el interior de los óvalos son los símbolos que indican el nombre de los aminoácidos. La insulina es una proteína muy pequeña. Debido a la posibilidad de combinar los aminoácidos en cualquier orden y cantidad es fácil comprender su versatilidad funcional. Estructura secundaria A medida que la cadena de aminoácidos se va ensamblando, empiezan a tener lugar interacciones entre los diversos aminoácidos de la cadena. Pueden formarse puentes de hidrógeno entre el hidrógeno del amino de un aminoácido y el oxígeno del carboxilo de otro. A causa de estas uniones la cadena polipeptídica se pliega, adoptando dos posibles configuraciones espaciales que constituyen lo que se conoce como estructura secundaria de una proteína. Estas dos configuraciones son las llamadas a-hélice y b-hoja plegada. Estas conformaciones no son las únicas que pueden adoptar las proteínas ya que en realidad cada proteína adopta una forma característica que depende de la secuencia lineal. Sin embargo las configuraciones antes mencionadas son las más frecuentes. La a-hélice es un tipo de espiral cilíndrico estabilizado por puentes de hidrógeno intracatenario, mientras que la b-hoja plegada está formada por cadenas polipeptídicas paralelas, mantenidas por puentes de hidrógeno intercatenarios. Fig. 2.56 - Esquema de una proteína presentando regiones con estructura secundaria en a-Hélice, en Hoja b-Plegada y regiones con enroscamientos aleatorios. Existen porciones de la cadena polipeptídica que no tienen estructura secundaria bien definida, y suelen denominarse enroscamientos aleatorios o ad random La proporciones de los distintos tipos de estructuras secundaria varían de una proteína a otra, sin embargo podemos decir que en la mayoría de las proteínas las formas a y b suelen constituir entre el 60 y el 70 % del polipéptido y un 30% conforman enroscamientos aleatorios Diversas secciones consecutivas de estructuras secundarias con frecuencia constituyen una estructura estrechamente asociada, esto es reconocido como otro nivel de estructura proteica que se denomina estructura supersecundaria. Existen varios ejemplos: el tipo b a b donde encontramos dos secuencias de b-plegada conectadas por una secuencia a. Dominios Se reconocen como agrupamientos aproximadamente esféricos con unos 50 a 150 aminoácidos que se forman por compactamiento local de la cadena polipeptídica. Una proteína de más de 200 aminoácidos en general contiene dos o tres dominios. Es difícil diferenciar la estructura supersecundaria del dominio, el dominio podría ser sólo una estructura supersecundaria o varias de ellas combinadas para dar un cúmulo compacto. El concepto de dominio es de utilidad ya que muchas proteínas distintas tienen dominios similares, de modo que parece ser que los dominios son unidades estructurales fundamentales, por ejemplo muchas proteínas distintas se enlazan con el NAD+ por medio de un dominio llamado pliegue de mononucleótido. Estructura terciaria Debido a la interacción de los grupos R, la cadena polipeptídica se pliega determinando una intrincada estructura tridimensional. En muchas proteínas la estructura terciaria le brinda a la proteína una forma globular, como por ejemplo en las enzimas, que son proteínas con función catalítica. Otras proteínas tienen estructura terciaria fibrosa y suelen tener largas hélices o extensas hojas plegadas. Estas proteínas fibrosas suelen tener función estructural como el colágeno. Fig. 2.57 - Tipos de enlace que estabilizan la estructura terciaria de una proteína El funcionamiento de las proteínas depende del plegamiento de sus moléculas que da lugar a configuraciones específicas y forma centros que pueden reconocer a la molécula con la cual la proteína se asocia o reacciona durante el metabolismo Fig. 2.58- Estructura de la molécula de hemoglobina (estructura cuaternaria) . Formada por dos cadenas de a-hemoglobina y dos cadenas de b-hemoglobina. Cada cadena transporta una molécula de oxígeno Estructura cuaternaria Muchas proteínas presentan este tipo de estructura, que es el grado máximo de organización proteica y consiste en dos o más cadenas polipeptídicas unidas generalmente mediante enlaces débiles. Estas proteínas se denominan oligoméricas o multiméricas y se las designa según el número de cadenas polipeptídicas que intervienen en la estructura cuaternaria. Por ejemplo, una proteína formada por cuatro subunidades es un tetrámero, como es el caso de la hemoglobina. Cada una de las subunidades proteícas, tienen su propia estructura terciaria. Funciones Biológicas de las proteínas Las proteínas dirigen la totalidad de los procesos celulares, incluso su propia síntesis. Las funciones de mayor importancia de las proteínas en los seres vivos son: Función estructural, como el colágeno, la tubulina de los microtúbulos, las de las cápsides virales, etc. (Tabla 2.7). Las moléculas de colágeno son ejemplos típicos de las proteínas simples fibrosas. Son la clase de proteínas más abundantes de nuestro cuerpo, son componentes de la matriz extracelular del tejido conectivo, de modo que las podemos encontrar en tendones, ligamentos, membrana basal, etc. Aunque existen distintos tipos de colágeno que se diferencian en las secuencias de aminoácidos y en las proporciones con que se encuentran los mismos, podemos hacer una generalización acerca de su estructura. El colágeno es una proteína fibrosa que posee una estructura de orden superior. Esta formado por unidades compuestas por tres cadenas polipeptídicas de aproximadamente 1000 aminoácidos cada una. Un tercio de esos aminoácidos está constituido por la glicina, prolina e lisina hidroxiladas, constituyendo una estructura rígida. El procolágeno, su unidad precursora, es secretado por el fibroblasto a la matriz extracelular junto a dos enzimas. Estas enzimas catalizan la separación de los extremos de la molécula de procolágeno para producir la triple hélice de tropocolágeno. Las moléculas de tropocolágena se asocian espontáneamente formando microfibrillas. Las microfibrillas se empaquetan unas junto a otras para formar fibras de colágeno maduro. Otro ejemplo de proteínas simples fibrosas lo constituyen las queratinas, que dan protección externa (piel, uñas, cabello, cuernos, etc.). Son producidas por las células epidérmicas. En su estructura secundaria es en gran parte a-hélice, en el caso particular de las queratinas del cabello encontramos en su estructura primaria un gran número de cisteínas ( en el R contienen grupos SH) lo que permite la formación de puentes disulfuro, que son uniones covalentes que se dan entre dos grupos SH y que estabilizan la estructura proteica. El calor o el tratamiento con determinados productos químicos pueden reducir los puentes disulfuro, o bien formar puentes nuevos, estirando u ondulando el cabello.
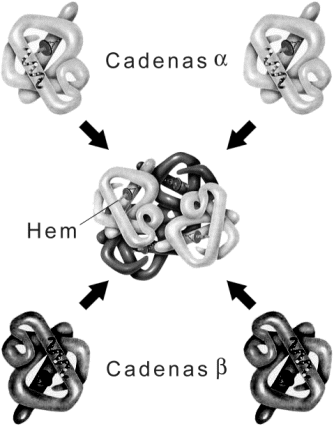
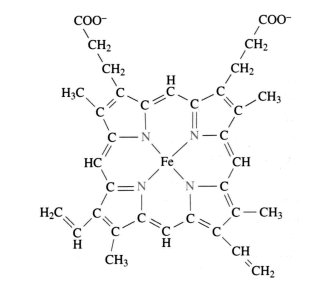
Función Reguladora: como las ciclinas que controlan el ciclo celular y los factores de transcripción que regulan la expresión de los genes. Función Motora: actina y miosina del músculo. Función de Transporte: Globulinas en general, hemoglobima, mioglobina y las lipoproteínas son algunos ejemplos. Fig. 2.59 - Grupo Hemo, presente en la hemoglobina y la mioglobina. La hemoglobina y la mioglobina son proteínas globulares conjugadas, es decir que en su estructura encontramos a parte del polipéptido un grupo no proteico que en este caso corresponde al grupo Hemo. La mioglobina consta de una sola cadena polipeptídica asociada a un grupo hemo que es el responsable de la unión del oxígeno, en tanto que la hemoglobina está formada por cuatro cadenas polipeptídicas cada una con su correspondiente grupo hemo. Por lo tanto la hemoglobina presenta estructura cuaternaria lo que le permite variar su afinidad por él oxigeno, la cual se ve afectada por el pH sanguíneo, la temperatura y la concentración de 2,3 DGP (2,3- difosfoglicerato). Función de Reserva: La ovoalbúmina, componente principal de la clara de huevo o la gliadina del trigo. Función de Receptores: como las proteínas receptoras de membrana. Función Enzimática: La enzimas catalizan todas las reacciones metabólicas. Dada su importancia biológica, este tema será tratado con más detalle en el próximo capítulo. Función de Defensa: Los anticuerpos son proteínas simples globulares y son sintetizadas por las células plasmáticas ( linfocitos B activados), son también conocidas como inmunoglobulinas o gamaglobulinas. Estas proteínas presentan gran diversidad ya que cada anticuerpo es específico para un determinado antígeno. Sin embargo, podemos mencionar que en general están compuestas por cuatro cadenas polipeptídicas dos contienen 220 aminoácidos (cadenas livianas) y las otras más largas con 440 aminoácidos cada una (cadenas pesadas). Función de mensajeros químicos: La mayor parte de las hormonas son proteínas o glucoproteínas. También ciertos aminoácidos, derivados de aminoácidos y oligopéptidos son neurotransmisores en el sistema nervioso. Desnaturalización de las proteínas Se denomina así a la pérdida de la estructura tridimensional de las proteínas. Es decir su estructura secundaria, terciaria o cuaternaria si la tuviera. Son agentes desnaturalizantes el calor, ácidos y bases fuertes, radiaciones, etc. La desnaturalización no afecta la estructura primaria, estabilizada por enlaces covalentes. En condiciones extremas de pH y temperaturas se pueden llegar a romper los enlaces peptídicos de manera que se rompe la estructura primaria, este proceso se denomina hidrólisis. La desnaturalización proteica es útil desde el punto de vista clínico ya que con frecuencia es utilizada en distintos procedimientos. Un ejemplo lo constituye la esterilización de elementos quirúrgicos, en donde el calor destruye las proteínas de los microorganismos, lo mismo que algunos desinfectantes como el alcohol. actividades de autoevaluación 1. ¿Qué es un nucleótido? 2. ¿Qué función cumple el ATP? 3. ¿Que función cumplen el NAD y el FAD? 4. ¿Que nucleótidos intervienen en la estructura del ADN? 5. ¿Cuales son las diferencias estructurales entre el ADN y el ARN? 6. ¿Qué postula el modelo de Watson y Crick? ¿Qué importancia tiene en la duplicación del ADN? 7. Dibuja una doble hélice de ADN realizando los siguientes pasos: a) Haz un espiral destacando lo que iría por delante del papel con un trazo más grueso: b) comprueba que el espiral gira a la derecha: c) construye otro espiral como el anterior, pero desplazado ligeramente hacia arriba, d) señala los extremos de cada cadena; e) coloca los peldaños y señala sobre el dibujo a qué corresponde y dónde se situarán las pentosas y los fosfatos. 8. Diseña una secuencia de 10 bases en una de las cadenas del ADN que acabas de realizar. ¿Cuál sería la secuencia de la cadena complementaria? ¿Y la del ARN que se podría formar con cada una de las cadenas? ¿Cuántas secuencias de ADN sería posible obtener? ¿Qué longitud tendría este ADN 9. ¿Cuáles son las fuerzas que intervienen en el mantenimiento de la estructura tridimensional de una proteína? 10. Escriba la estructura general de un aminoácido. ¿Cuál es la importancia del grupo R en la estructura de las proteínas? 11. ¿Qué entiende por estructura primaria? 12. ¿Qué tipos de aminoácidos conoce, en que se basa esa clasificación? 13. ¿Qué estructuras se ven afectadas durante la desnaturalización proteica? 14. ¿Qué proteínas con función estructural puede mencionar? 15. ¿Todas las proteínas poseen estructura cuaternaria? 16. ¿Qué determina la forma tridimensional de una proteína? Preguntas de opción múltiple 1. Un nucleótido está formado por: a. un azúcar de 4 carbonos, un grupo fosfato y una base carbonada b. un azúcar de 5 carbonos, un grupo fosfato y una base nitrogenada c. un azúcar de 5 carbonos, un grupo fosfato y una base hidrogenada d. un azúcar de 6 carbonos, una base nitrogenada y un grupo fosfato e- e. ninguna es correcta. 2. ¿Cuáles son los pares de bases que puede encontrar en la doble hélice del ADN?: a. A-G b. A-C c. A-T d. T-U e. G-T 3. ¿ Qué fuerzas estabilizan la doble hélice del ADN? : a. puentes de hidrógeno b. interacciones hidrofóbicas c. interacciones polares d. todas son correctas e. ninguna es correcta. 4. En el experimento de Chase la marca radiactiva del ADN: a. aparece fuera de la célula, comprobando que el ADN almacena la información genética b. está dentro de la célula, comprobando así que es la molécula que almacena la información c. aparece fuera de la célula demostrando que es patógeno d. aparece dentro de la célula demostrando que es estable e. ninguna es correcta 5. El ARN ribosomal : a. forma parte de los ribosomas b. se sintetiza en los ribosomas c. se une a los ribosomas d. interviene en la maduración del ARNm e. ninguna es correcta 6. Podemos encontrar ARN de doble cadena en: a. las células procarionte b. en cloroplastos y mitocondrias c. en algunos virus d. en células vegetales e. todas son correctas 7. La unión peptídica se produce entre: a. el grupo alcohol de un monosacárido y el grupo ácido de un ácido graso b. el grupo amino de un aminoácido y el grupo ácido del mismo aminoácido c. el grupo amino de un aminoácido y el grupo ácido de otro d. el grupo amino de un aminoácido y el grupo fosfato e. ninguna es correcta Bibliografía l Alberts, B et al. (1996) Biología Molecular de la Célula. 3ra Edición. Ediciones Omega S.A.Barcelona. l Campbell, N. (1997) Biology. 4th Edition. the Benjamin Cummings Publishing Company. Inc. California. l Curtis y Barnes (1992). Biología. 5ª Ed. Bs.As. Editorial Médica Panamericana. l Harper, (1995) Manual de Bioquímica. Ediciones El Manual Moderno. México. l Karp, G.. (1998) Biología Celular y Molecular. Ed. Mc Graw Hill Interamericana. México. l Kuchel,p y Ralston, G. (1994) Bioquímica General. Serie Schaum. Ed. McGraw-Hill. México. l Smith and Wood. (1998) . Moléculas Biológicas. Ed.Addison-Wesley. Iberoamericana S.A. l Solomon y col. (1998) . Biología de Villee. 4ª. Ed.McGraw-Hill. Interamericana. México. l
Stryer, L.. (1995) Bioquímica. Ed. Reverté. España. [1] En la naturaleza se han encontrado aproximadamente 150 aminoácidos, pero sólo 20 de ellos están presentes en las proteínas. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||